“Knowing is not enough, we must APPLY. Willing is not enough, we must DO.” Bruce Lee
Avoir l’étude théorique sur l’algorithme K-Means pour le Clustering, je ne pouvais pas vous laisser en plan et ne pas chercher une application.
En revanche, ce n’est pas aussi évident d’avoir une application directe de cet algorithme. Beaucoup de recherches académiques existent, mais très peu permettent de créer facilement un modèle de trading simple que l’on pourrait backtester.
Source
Avant toute chose, je vais rendre à César ce qui est à César.
Au fil de mes recherches, je suis tombé sur un site équivalent à ce que je fais (mais en Anglais), et dont la stratégie qu’il a implémentée se rapproche très exactement de ce que je voulais vous proposer.
J’ai donc décidé avec son accord d’utiliser son modèle, et de l’appliquer au CAC (lui le fait sur le S&P500). En revanche, je ferais l’explication et la présentation avec ses exemples à lui. Ceux qui sont à l’aise en Anglais pourront trouver ça redondant, mais pour les autres, je n’ai pas forcément beaucoup mieux à dire, donc autant faire avec ce qui existe déjà et qui est bien fait.
Cette personne est David Bergstrom, et l’article qu’il a écrit pour QuantNews (qui est celui que j’utilise) est le suivant : https://www.quantnews.com/k-means-clustering-creating-simple-trading-rule-smoother-returns/
Vous pouvez également voir sa plateforme ici : Build Alpha
Prerequis
Ceci étant dit, rentrons dans le vif du sujet maintenant. Les prérequis sont les suivants :
- ATR, car on utilisera cet indicateur : Average True Range
- Of course, K-Means : Clustering 101 : l’algorithme K-Means
- les prérequis de ces articles : par exemple, nous utiliserons aussi une SMA, censé être connue aussi pour l’ATR
On pourra se contenter de ces deux-là car vous verrez que nous ne ferons pas le genre de backtests habituels avec le GoingStrikerBot.
Explication
Nous avons vu que l’algorithme K-Means permet d’identifier des groupes possédant des caractéristiques communes : les clusters.
L’idée ici est d’utiliser les caractéristiques de volatilité et voir si l’identification de certains profils permet de faire une stratégie rentable.
Paramètres
Le premier paramètre de notre algo est relativement simpliste : on choisit 3 clusters. On peut naturellement penser qu’ils convergeront vers des groupes de faibles / moyennes / fortes volatilité. Ce choix est totalement arbitraire (avec un minimum de logique sous-jacente quand même) et libre à vous de choisir un autre nombre de clusters.
Il faut maintenant choisir les distances. Pour une illustration plus simple, mon camarade a décidé de choisir 2 dimensions, afin de pouvoir ramener la distance à une distance Euclidienne dans un plan :
- en X : Volume / SMA_20 (Volume). La pertinence du volume est plutôt reconnue et est assez logique : lorsqu’il y a un volume supérieur aux volumes récents, c’est qu’il se passe quelque chose, et ça va se ressentir dans les variations de cours.
- en Y : (High – Low) / ATR_20. C’est un peu le même principe mais appliqué directement à la volatilité plutôt qu’au volume.
Données
Les données utilisées sont celles du future S&P 500 depuis 1997.
Pour limiter l’overfitting, il utilise :
- In-Sample data pour l’algo : avant 2015
- Out-of-Sample data pour tester la stratégie : après 2015
Là aussi, le choix des périodes est arbitraire. On est en droit de se demander si 1997-2015 c’est pertinent pour prévoir 2015-2018, mais ce genre de questions n’a pas de réponse absolue pour l’instant. Le mieux qu’on puisse faire, c’est d’y répondre empiriquement, et d’utiliser ce qui fonctionne.
Implémentation
Pour l’implémentation, j’ai utilisé un module POC et Machine Learning du GoingStrikerBot, qui me permet de faire les travaux de Machine Learning / Data Science en Python. Il n’y a malheureusement pas encore d’implémentation de K-Means et des stratégies qui en découle dans le GoingStrikerBot. Si je vois qu’on arrive à un point où on ne peut plus s’en passer, je l’implémenterai.
Je ne remettrais pas le code Python ici, vous pouvez l’obtenir dans l’article originel.
Apprentissage
1ere étape : calcul des clusters sur les données In-Sample.
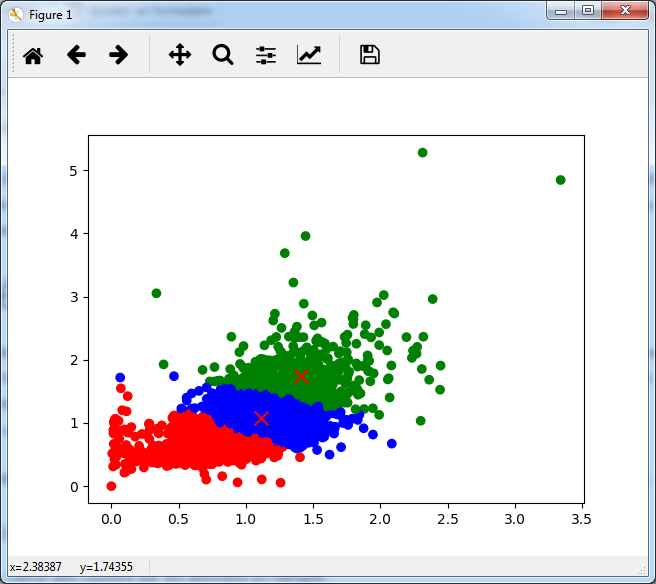
On peut voir qu’effectivement, les clusters correspondent aux volatilités faibles / moyennes / fortes.
Voyons si d’après ces clusters on peut avoir une stratégie rentable… Plutôt qu’un backtest réel, le choix a été fait de simplement cumuler les variations des journées selon le cluster :
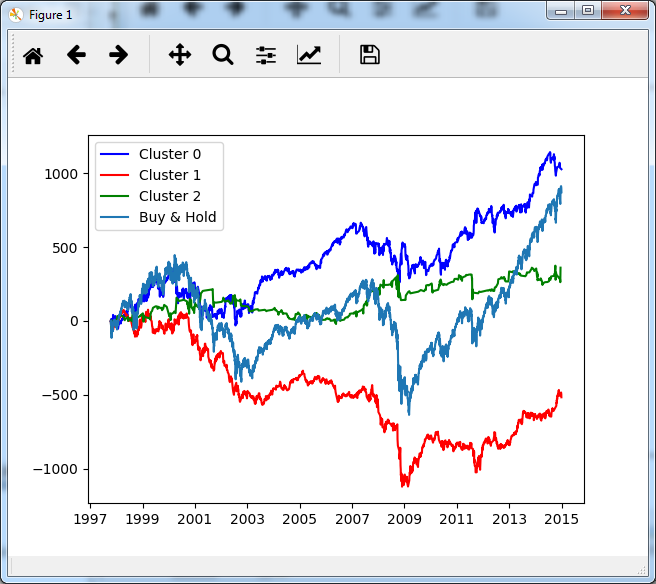
Le suivi du Cluster 0, qui correspond aux volatilités moyennes (le code couleur est le même) semble être le plus rentable. Si on tente maintenant le suivi du cluster correspondant dans la période Out-sample :
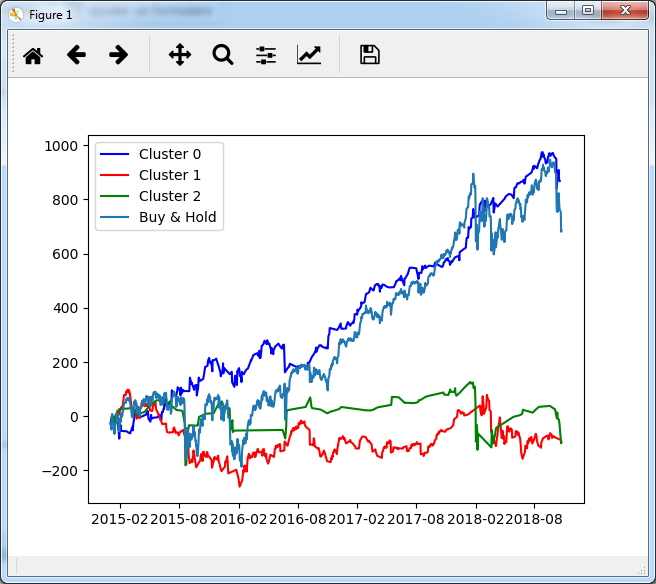
Nous pouvons voir que cette stratégie réalise une bonne performance nette.
En revanche, je ne suis pas du tout convaincu par l’Alpha de cette stratégie. Elle a un peu moins de drawdown que le simple Buy & Hold, et subit un peu moins les mouvements forts, mais l’Alpha final est loin d’être grandiose.
Dans l’article d’origine, il continue sur cette base en utilisant des indicateurs supplémentaires en tant que filtres pour améliorer les points d’entrées et de sorties. Mais personnellement, je vous propose autre chose.
Adaptation CAC 40
Pour des raisons de facilité d’accès au marché, je vais l’adapter sur le CAC 40 (et un peu par chauvinisme aussi :)) : Données CAC 40
Malheureusement, pour des raisons de qualité de données, la période In-sample est fortement réduite : elle ne commence qu’en 2004, car il n’y a pas d’information de volume avant. Il y a donc moins de points d’apprentissage, mais les clusters sont globalement équivalents. Voici ce que ça donne à l’apprentissage :

Les couleurs sont respectivement bleu, vert, rouge pour les volatilité faibles, moyennes, fortes. C’est encore la volatilité moyenne qui est la plus rentable. Et maintenant, out of sample :

J’ai un peu changé le code couleur (bleu = volatilité moyenne) afin de voir plus clairement ce qu’il en est, en particulier sur la période de fin. Finalement, nous pouvons nous rendre compte que cette stratégie suit à peu de chose près le benchmark, ce qui la rend assez peu intéressante telle quelle.
Mais ce n’est qu’une approche de l’utilisation de K-Means adaptée la finance. Ce sujet peut être (et sera sûrement) creusé un peu :
- l’idée des filtres de mon camarade est plutôt bonne et permet des optimisations comme vous pouvez le voir sur son article, il est possible que j’essaie de faire quelque chose dans le genre également
- d’autres approches complètement différentes existent : par exemple, on peut clusteriser les barres OHLC selon leur taille (rapport High / Low) et étudier les liens entre les clusters correspondant. Si on peut déduire des règles comme “une longue barre est très souvent suivie d’une autre longue barre”, il y a un potentiel de stratégie…
La littérature est longue, je nous souhaite bon courage 🙂
Je voudrais dédicacer cet article à O. Sosno ! C’était mon binôme sur K-Means à l’école ! J’espère que les articles correspondants lui rappelleront des souvenirs 🙂